
2024.05.14
パフォーマンス分析

はじめに
本テーマの構成
本テーマは、3本の記事で構成しています。
1本目の記事では、コンテナ技術の普及に至った背景から、Kubernetesを構成するレイヤーの説明、オートスケーリング機能によるリソースの自動調整の機能を紹介しました。
本記事以降で、「Dynatrace」を用いて、Kubernetesを対象に分析する手法について説明します。
本記事にて、パフォーマンス分析の観点から、各画面や手法を紹介します。(下記目次の2に該当します。)
3本目の記事で、アラート機能に焦点を当てて、各種設定やIT運用にどのように役立てられるのかを説明します。
本テーマ全体の目次
全体を通しての目次は、下記の通りです。
[目次] ――――――――――――――――――――――――
1. Kubernetesとは、Kubernetesの各レイヤーについて
1-1. Kubernetesとは何か
1-2. コンテナ技術とDocker
1-3. Kubernetesの登場
1-4. Kubernetesの構成
1-5. Kubernetesのオートスケーリング機能について
2. Dynatraceでできること(パフォーマンス分析)
2-1. Dynatraceを用いたKubernetesの性能管理
2-2. DynatraceでのKubernetesの稼働分析
2-2-1. Cluster単位の分析
2-2-2. Namespace単位の分析
2-2-3. Workload単位の分析
2-2-4. Node単位の分析
2-2-5. Pod単位の分析
2-2-6. Container単位の分析
3. Dynatraceでできること(アラート機能)
3-1. Cluster単位の検知
3-2. Namespace単位の検知
3-3. Node単位の検知
3-4. Workload単位の検知
4. まとめ
――――――――――――――――――――――――
本記事では、パフォーマンス分析の観点から、Dynatraceの各画面や手法を紹介します。
2.Dynatraceでできること(パフォーマンス分析)
2-1. DynatraceでのKubernetesの性能管理
Dynatraceは、Kubernetes環境全体をリアルタイムに監視し、アプリケーションのパフォーマンスを確認して問題を迅速に特定することができます。
Dynatraceは、コンテナ化されたアプリケーションの動作、ネットワークトラフィック、インフラストラクチャの状態など、Kubernetes Cluster内の様々な要素に関する豊富なメトリクスを収集して可視化します。
これにより、開発者や運用チームはパフォーマンスのボトルネック、リソースの過剰または不足、エラー発生の原因など、多岐にわたる問題を効率的に把握し、対応することが可能になります。
監視をDynatraceで行うためには、"OneAgent"と称されるエージェントを各Podに適用する必要があります。
導入手段には複数の選択肢が存在しますが、"Dynatrace Operator"を用いる方法を選択することで、新規に追加されるPodへのエージェントの手動導入を省略し、自動でエージェントを配布し監視対象に加えることが可能になります。
このアプローチにより、NodeやPodを継続的に追跡し監視する作業が容易になり、管理の手間を軽減できます。
2-2. DynatraceでのKubernetesの稼働分析
各レイヤ―の分析項目を紹介します。
2-2-1. Cluster単位の分析
各レイヤーについて、概要の画面で大枠を確認し、ドリルダウンして詳細な分析画面に遷移することができます。
Clusterについて、概要の画面から下記のような項目が確認できます。
画面遷移:[Infrastructure Observability > Kubernetes]
・各Clusterに割り当てられたリソースに対する使用率
・各Cluster内で割り当て可能なリソースの合計値
・各Clusterを構成するオブジェクト情報(Namespace、Workloads、Service、Nodes)
Clusterに割り当てられたリソースに対して、どれだけ使用しているか、また各Clusterを構成するオブジェクト情報も、併せて把握することができます。
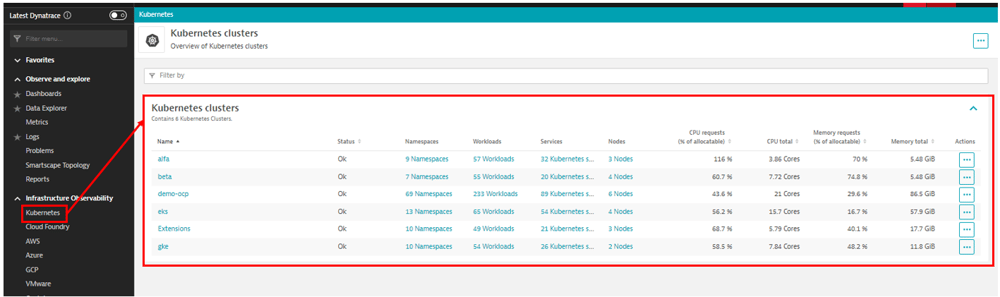
【図1】Cluster概要
また、任意のClusterを対象にした分析画面では、下記のような項目が確認できます。
画面遷移:[Infrastructure Observability > Kubernetes>任意のCluster]
[Node analysis]
・時系列グラフでのNodeのリソース使用率、Requests(※1)、limits(※2)
・時系列グラフでのPod数、Podの割り当て可能数、Containerのリスタート回数
コンテナについて、DynatraceのUI表記に準じて以降は「Container」と表記します。
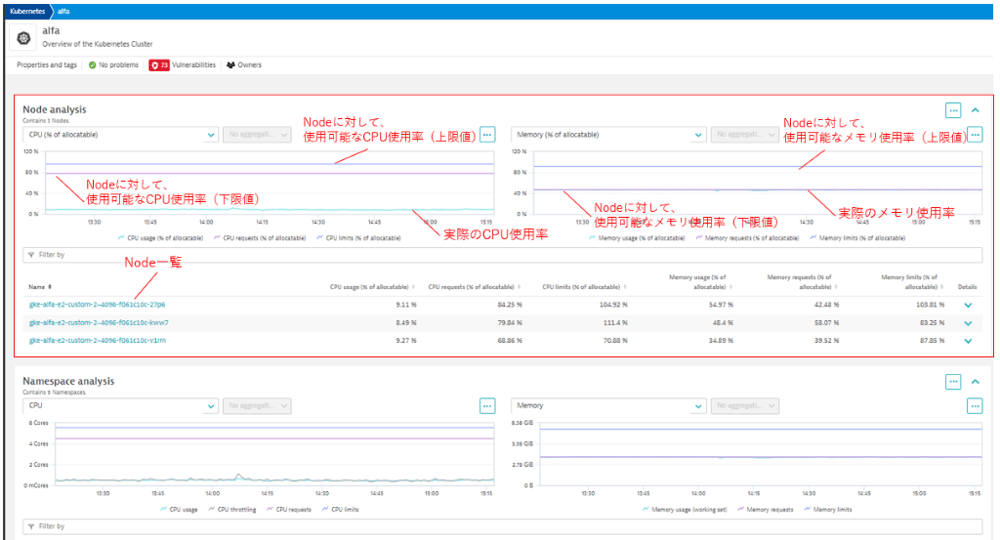
【図2】任意Clusterの概要(Nodeを対象とした時系列グラフ及び関連データ)
分析について、ユースケースをご紹介します。
下記Clusterにある3つのNodeの全てで実際のCPU使用率が低く、割り当てられたCPUリソースに対して、実際にはほとんど使われていないことが分かります。
ある程度の期間における稼働状況から、CPUリソースの余剰を判断し、該当Nodeのリソース割り当てを減らすことを検討するなどといったデータの活用が可能です。
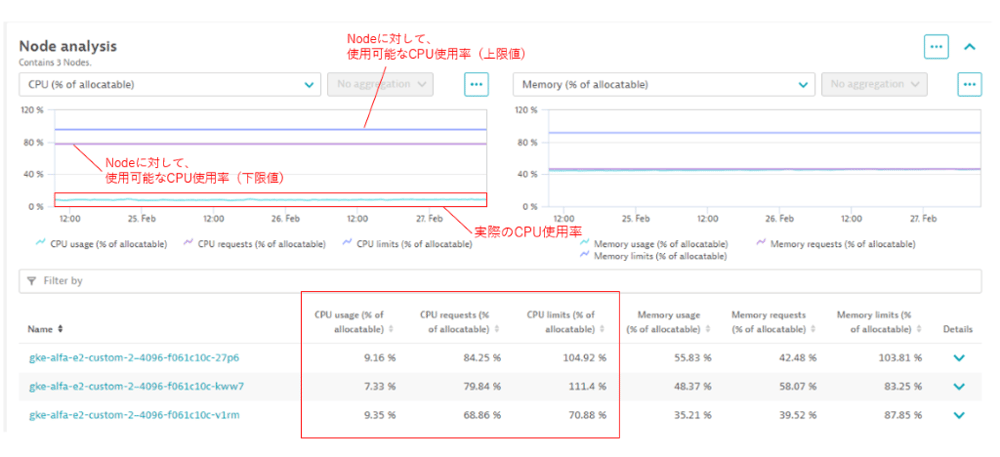
【図3】任意Clusterの分析画面(Node分析のユースケース)
大規模なClusterでは、Cluster全体のリソースを適切に分配するために、ClusterのサイジングやNodeの数を考慮することが重要となります。
Kubernetesでは、オートスケーリングする単位はPodもしくはNodeであり、Clusterでそれらが割り当て上限に達した場合にはそれ以上スケーリングすることはできません。
稼働状況を監視することで、この上限に達する前に対策を取ることが可能です。
[Namespace analysis]
「Namespace」とは、1つのClusterを仮想的に分割した単位のことを表します。
複数のNode間で動くPodをグルーピングしており、例えば、担当チームの作業単位で分割することができます。
多くのユーザーがいる環境でリソース管理を容易にするために、任意で作成するといった使い方がされます。
過多になると、管理コストが余分に増えてしまいます。
・時系列グラフでのNamespaceのリソース使用率、CPU throttling(※3)、Requests、limits
Namespaceへのリソースの割当に対して、使用率が把握できます。
CPUリソースが不足しているかどうかは、throttlingの発生より把握できます。
・時系列グラフでのPodの数(フェーズ毎)、Podのクォータ、Workload数(タイプ毎)、Containerのリスタート回数
Podの上限に対して、現在のリソース使用量が把握できます。
Containerについて、limitを超過してリソースを利用することやアプリケーションのエラーなどを理由に、再起動する場合があります。
再起動が頻繁に発生している場合、パフォーマンスが低下する原因となるため、適切な監視とトラブルシューティングを行う必要があります。
(※1)Requestsは、Podが最低限必要とするCPUとメモリの容量です。
(※2) Limitsは、Podの負荷が高まった際に使えるCPUとメモリの最大容量です。
(※3) throttlingとは、各Containerに対して、リソースの使用量が設定されたlimitを超えたときに発生する現象のことです。
throttlingが発生すると、Containerのプロセスは必要なリソースサイクルを全て得られないため、パフォーマンスが低下する可能
性があります。
任意のNamespaceを対象とした分析画面の見方は、後述します。
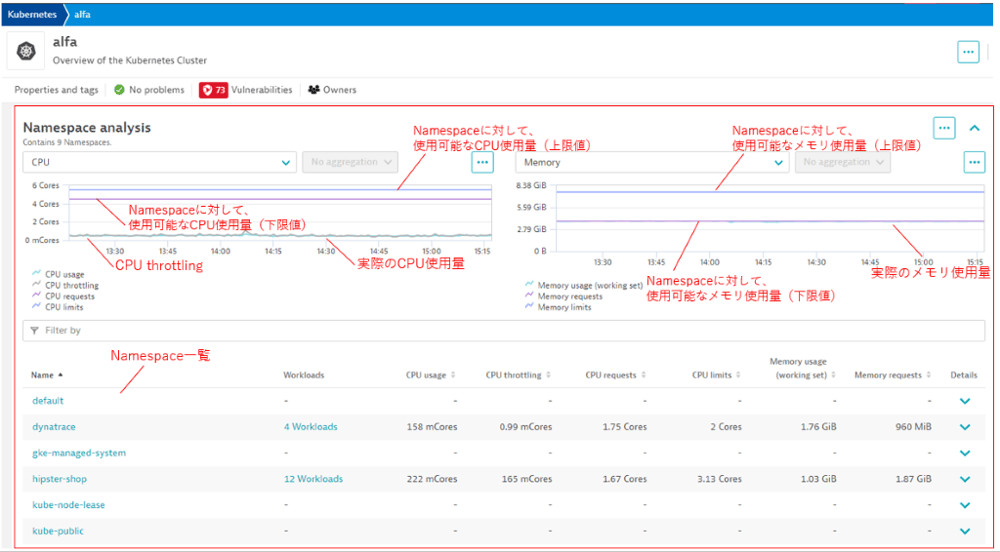
【図4】任意Clusterの分析画面(Namespaceを対象とした時系列グラフ及び関連データ)
また、Cluster概要画面から、Kubernetes Serviceの単位で構成情報を確認することができます。
KubernetesにおけるServiceは、クライアントからのリクエストトラフィックをPodへ転送する機能を提供します。
Podは停止、起動を行うたびにIPアドレスが変化し、Podと外部が安定した通信を行うためにはPodのIPアドレスを代表IPアドレスに変換するServiceが必要となります。
画面遷移:[Infrastructure Observability > Kubernetes>任意のClusterに紐づけられたKubernetes service]
・Kubernetes servicesに関連するCluster情報(名称、IP、Port)
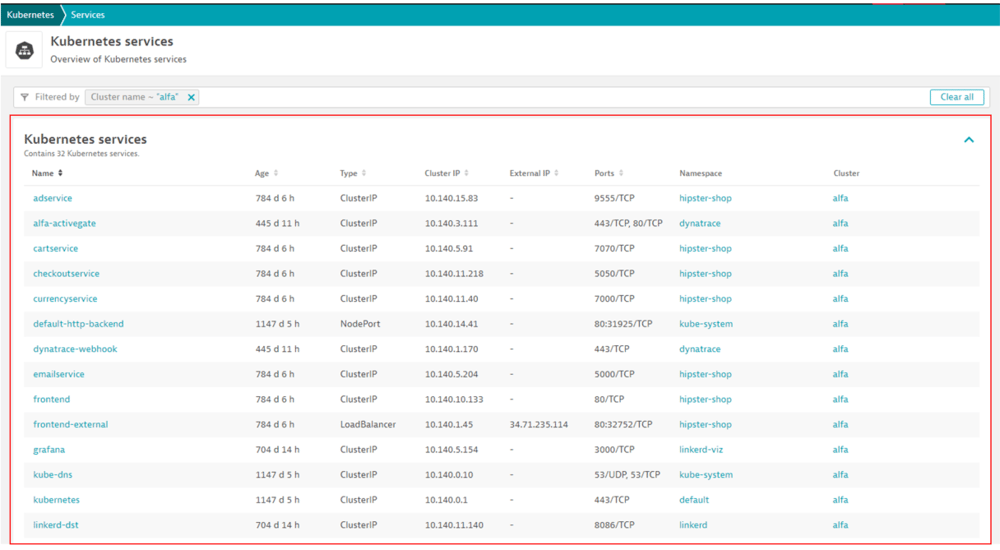
【図5】Kubernetes Service概要画面
2-2-2. Namespace単位の分析
Kubernetesでは、Namespace単位でリソース上限を設定することが可能です。
Namespaceを対象とした画面では、概要の画面から、下記のような項目が確認できます。
画面遷移:[Infrastructure Observability > Kubernetes>任意のClusterに紐づけられたNamespace]
・構成情報(1つのNamespaceに対して関連するCluster、Workloads、Kubernetes service)
・各NamespaceのRequests、limits
作成されたNamespaceについて、構成やリソースについて、一元的に把握することができます。
※Dynatraceで収集データを閲覧するにあたり、ユーザー毎に閲覧可能はデータを制限することもできます。
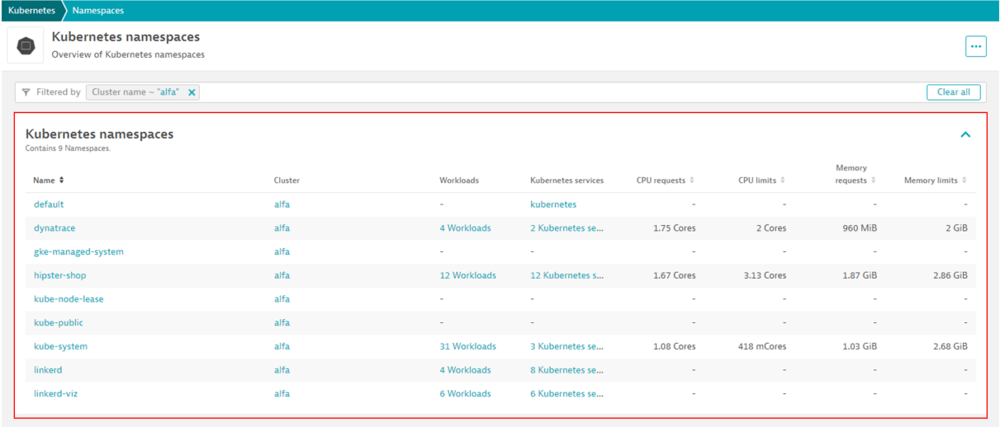
【図6】Namespace概要画面
また、任意のNamespaceを対象にした分析画面では、下記のような項目が確認できます。
[Resources analysis]
・時系列グラフでのNamespaceのリソース使用量、CPU throttling、Requests、limits
・時系列グラフでのPodの数、Podの割り当て可能数、Containerのリスタート回数
Namespaceは通常、ビジネスユニットで割当がされます。
ビジネスユニットで割り当てられているリソースの量と、実際の使用率を比較することができます。
Namespaceへのリソース割当に対して、使用率が把握できます。
CPUリソースが不足しているかどうかは、throttlingの発生より把握できます。
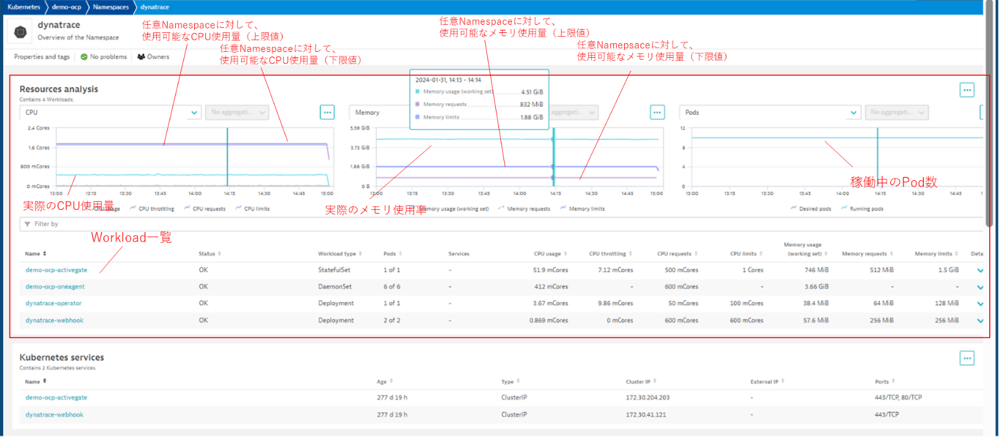
【図7】任意Namespaceの分析画面
2-2-3. Workload単位の分析
Kubernetesでは、Workload単位でリソース上限を設定することが可能です。
Workloadについて、概要の画面から、下記のような項目が確認できます。
画面遷移:[Infrastructure Observability > Kubernetes>任意のClusterに紐づけられたWorkload]
・各Workloadで稼働しているpod数
・Podにトラフィックを送信しているService数
・Workloadの関連情報(ステータス、種類、関連しているCluster)
Cluster上で実行されているWorkloadを対象に、関連オブジェクト(Pod数など)について、一元的に把握することができます。
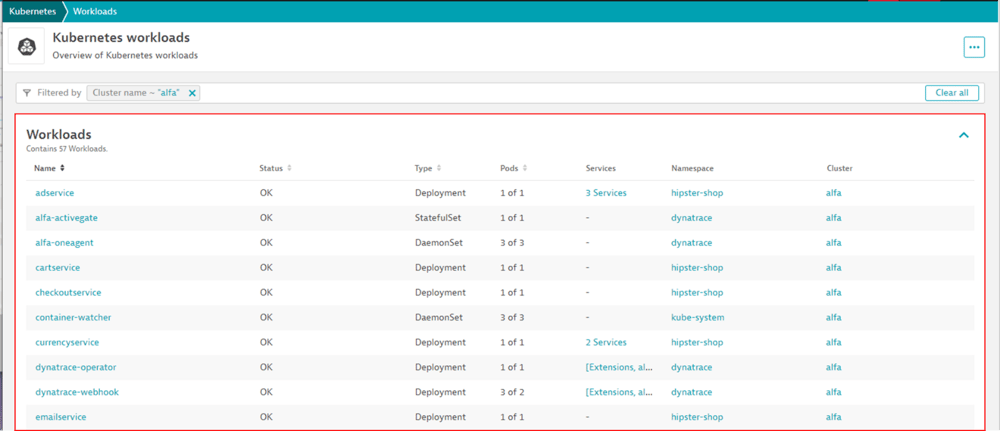
【図8】Workload概要画面
また、任意のWorkloadを対象にした分析画面では、下記のような項目が確認できます。
[Resources analysis]
・時系列グラフでのWorkload内のリソース使用量、CPU throttling、Requests、limits
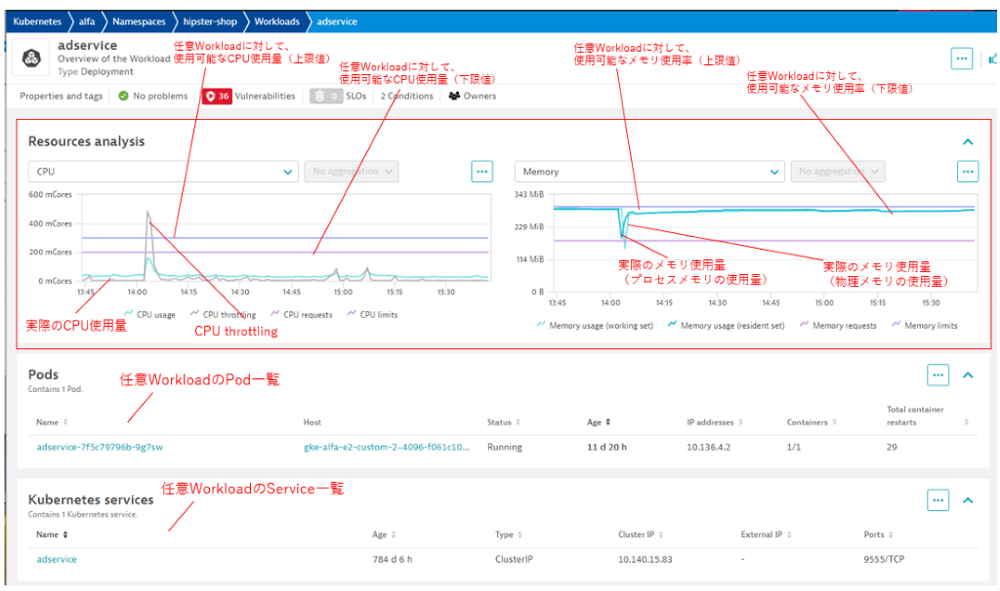
【図9】任意Workloadの分析画面
2-2-4. Node単位の分析
Nodeについて、概要の画面から、下記のような項目が確認できます。
画面遷移:[Infrastructure Observability > Kubernetes>任意のClusterに紐づけられたNode]
・各Nodeで稼働しているPod数
Nodeについて、構成や稼働状況を一元的に把握することができます。

【図10】Node概要画面
また、任意のNodeを対象にした分析画面では、下記のような項目が確認できます。
[Resources analysis]
・時系列グラフでのNodeのリソース使用量、CPU throttled、Requests、limits、割り当て可能な合計値(CPU、メモリ)
・時系列グラフでのPodの占有している数、Podの割り当て可能数、Containerのリスタート回数
・Podの関連情報(ステータス、稼働時間、IP、Container数)
Nodeへのリソース割当に対して、実際のリソース使用量が把握できます。
CPUリソースが不足しているかどうかは、throttlingの発生より把握できます。
必要に応じて、Node数を増減させることを検討します。
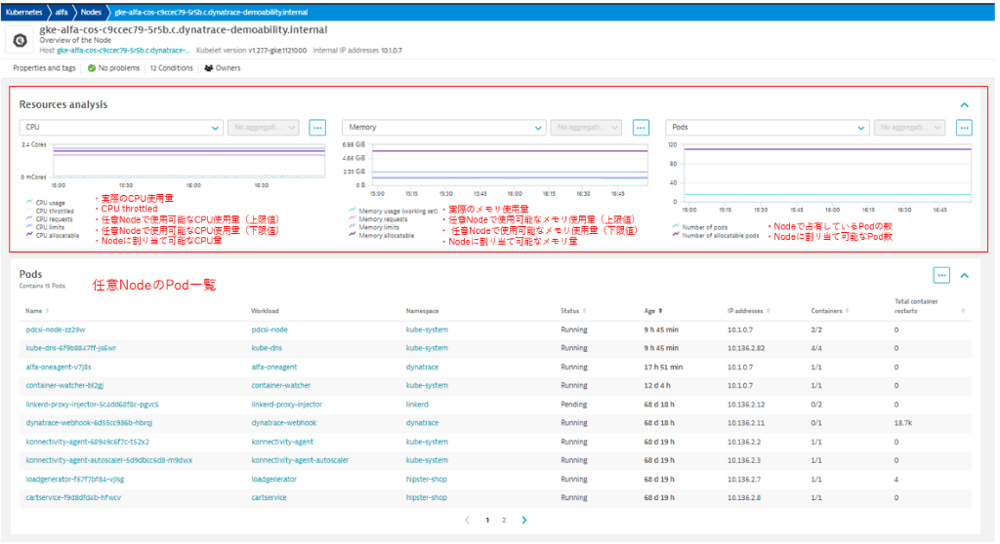
【図11】任意Nodeの分析画面
さらに、任意のNodeを対象に、イベントが発生している場合は併せて表示します。
・OOMKilling(Out Of Memory Killing)
Container内のプロセスが、limitで設定した値より多くのメモリを消費しようとすると、システムカーネルは、OOM(メモリ不足)エラーで、割り当てを試みたプロセスを終了します。
Dynatraceでは、メモリ不足によるkillが発生した場合、Containerレイヤーの単位から確認することができます。
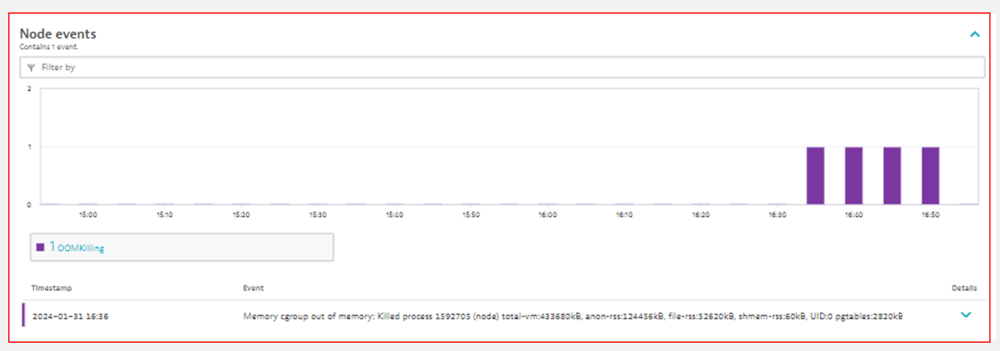
【図12】Node events分析画面
2-2-5. Pod単位の分析
Podについて、概要の画面から、下記のような項目が確認できます。
画面遷移:[Infrastructure Observability > Kubernetes>任意のClusterに紐づけられたNode>Pods]
・該当Nodeで稼働しているPodの情報(一覧、ステータス、種類)
・該当Nodeで稼働しているPodに紐づけられた情報(Cluster、Namespace、Workload、稼働時間)
Podについて、構成や稼働状況を一元的に把握することができます。
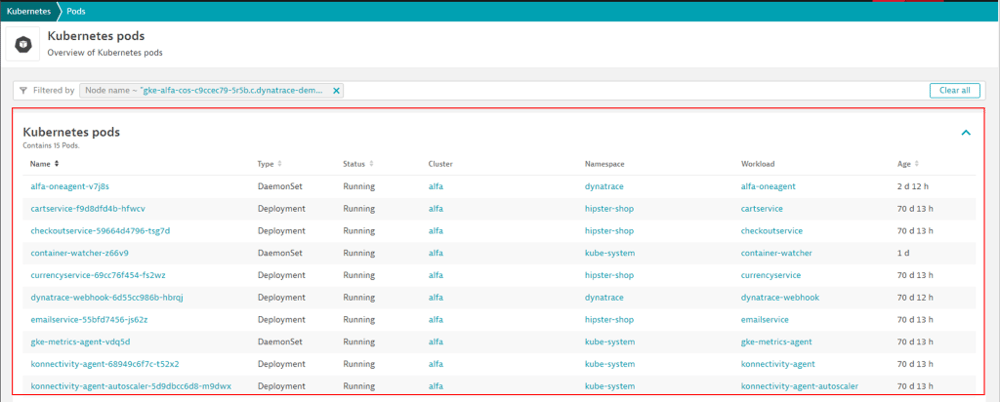
【図13】Pod概
また、任意のPodを対象にした分析画面では、下記のような項目が確認できます。
[Resources analysis]
・時系列グラフでのPodのリソース使用量、CPU throttling、Requests、limits
・OOM kills
・Containerのリスタート回数
Podの稼働状況より、アプリケーションが十分なリソースを取得しているかを確認ができます。
Pod数の増加はアプリケーションのスケーリング、デプロイ、フェイルオーバーといった要因によって引き起こされます。
稼働状況に応じて、Podの数やリソースについて、設定値を見直すことを検討します。
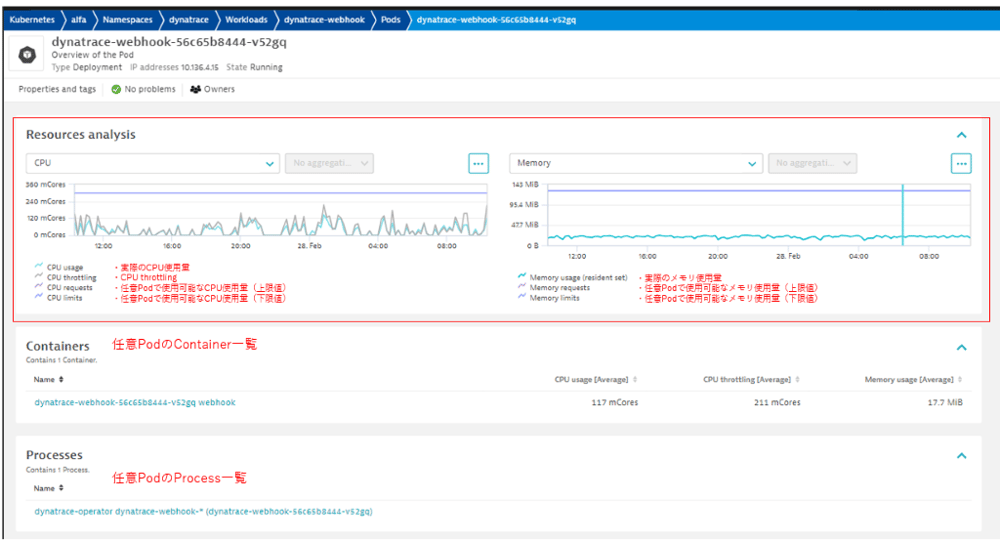
【図14】任意Podの分析画面
2-2-6. Container単位の分析
最も詳細な単位であるContainerについても分析が可能です。
画面遷移:[Infrastructure Observability > Kubernetes>任意のClusterに紐づけられたNode>Pods>任意のContainer]
特定のContainerを対象に分析した場合の画面を紹介します。
[Performances]
・時系列グラフでのContainerのリソース使用量、Requests、limits
・事例列グラフでのContainer CPU throttling
DynatraceではKubernetesの性能分析を、最も細かいContainer単位まで分析することができます。
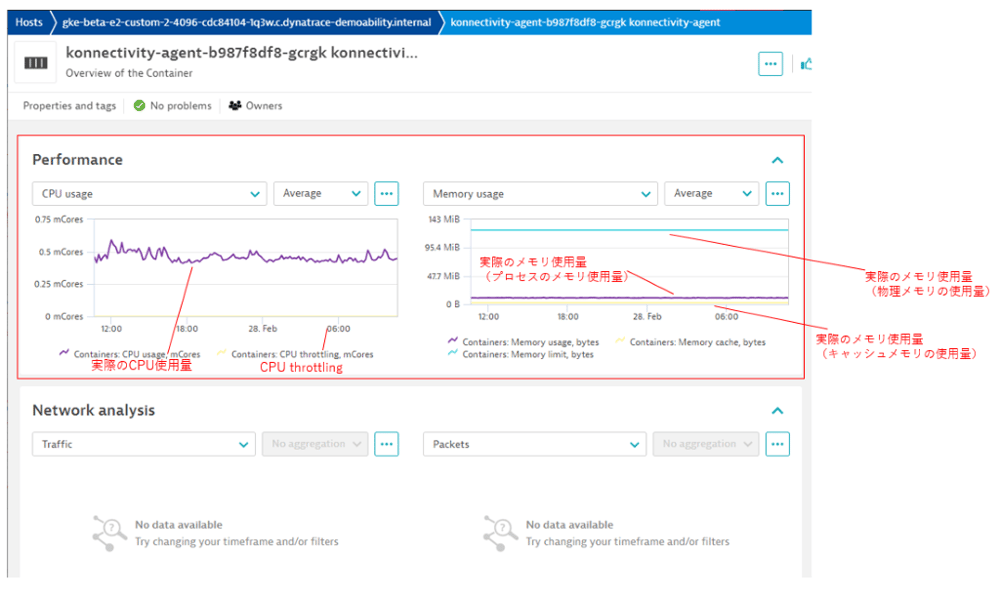
【図15】任意Containerの分析画面
また、Containerについて、ネットワーク関連のメトリクスも併せて取得可能です。
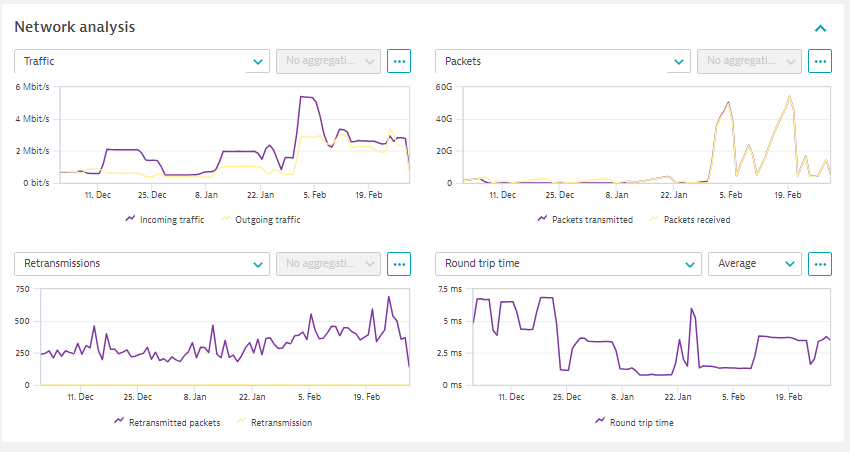
【図16】任意Containerの分析画面(ネットワーク分析)
<Data explorerのご紹介>
ここで、Dynatraceの機能である"Data explorer"をご紹介します。
Data explorerとは、データ分析の機能です。
たとえばContainerを対象にCPU使用率の高い順にリスト表示を行い、分析することができます。
分析方法は、弊社発行のTipsでも紹介していますのでご参照ください。#27 グラフ作成 -Data explorer-
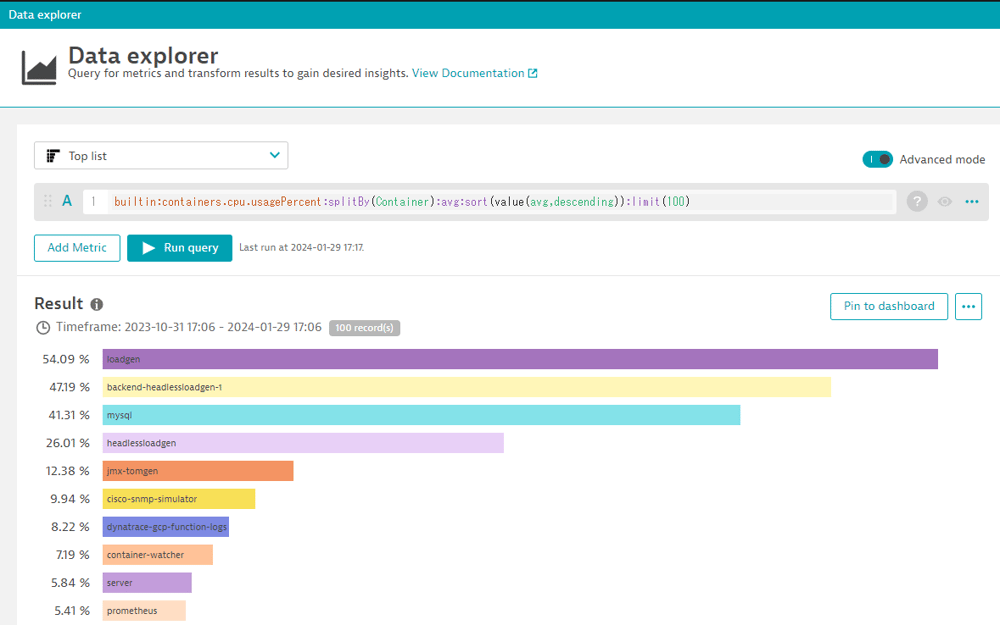
【図17】Data explorerによるContainer分析例
<Dashboardのご紹介>
最後に、Dynatraceの機能である"Dashboard"についてご紹介します。
Dashboardとは、Dynatraceで取得している各データを可視化し、一画面で閲覧できる機能です。
たとえば、リソース消費状況を色分けして表示することや、TOPリストによる表示があります。
予め用意されたDashboardを利用するほか、担当者ごとに任意で作成することも可能です。
Dashboardの作成方法は、弊社発行のTipsでも紹介していますのでご参照ください。#28 Dashboardの用途と作成方法
Kubernetesのリソース使用状況を俯瞰するDashboardについて、下記のようなサンプルがあります。
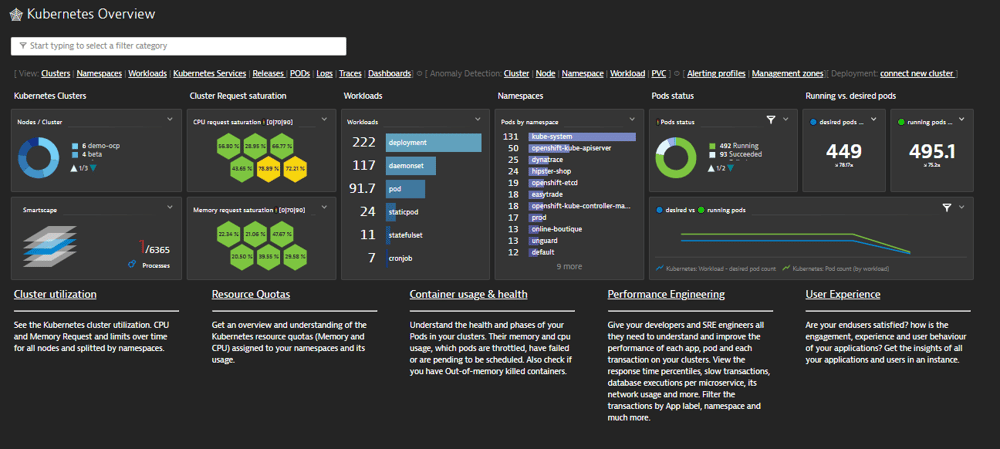
【図18】Dynatrace社のサンプルダッシュボード画面
次回の記事にて、Dynatraceのアラート機能に焦点を当てて、各種設定やIT運用にどのように役立てられるのかを説明します。
以上

執筆者
R.Y.
営業技術本部 技術サービス統括部 技術サービス1部
また、お客様環境にて性能問題が発生した際には、製品のアウトプットを利用し、問題解決に向けた調査/提案業務を実施
■経歴
2021年 入社
2022年 東京でのお客さまサポートを担当
主にシステムリソース情報からの性能管理サポート、APM製品を利用したユーザー体感レスポンスやアプリケーション視点での性能管理サポートに従事。現在に至る。
-

#16 サイジング事例
2024.01.25
DBサーバー更改において、更改後にどの程度のリソース割り当てが適正かを確認した事例をご紹介します。
-

#12 SQL Server搭載サーバーのCPU負荷上昇の原因分析
2020.12.10
SQL Server搭載サーバーのCPU負荷上昇について、オープンシステム向け性能管理ソフトウェア ES/1 NEO CSシリーズを活用した分析事例をご紹介します。
-

#2 DBサーバー負荷上昇の原因分析
2020.02.13
DBサーバーの負荷が想定より高くなる事象について、オープンシステム向け性能管理ソフトウエア ES/1 NEO CSシリーズを活用した分析事例をご紹介いたします。