
2024.05.14
Kubernetesの概要と各レイヤーの解説

はじめに
近年、IT運用の現場でKubernetesに対する注目が高まっています。
今回は「Dynatraceを用いたKubernetes分析」をテーマにご紹介いたします。
本テーマの構成
本テーマは、3本の記事で構成しております。
本記事にて、コンテナ技術の普及に至った背景から、Kubernetesを構成するレイヤーの説明、オートスケーリングによるリソースの自動調整機能を紹介します。(下記目次の1に該当します。)
以降の記事で、「Dynatrace」を用いて、Kubernetesを対象に分析する手法について説明します。
2本目の記事で、パフォーマンス分析の観点から、各画面や手法手法を説明します。
3本目の記事で、アラート機能に焦点を当てて、各種設定やIT運用にどのように役立てられるのかを説明します。
本テーマ全体の目次
全体を通しての目次は、下記の通りです。
[目次] ――――――――――――――――――――――――
1. Kubernetesとは、Kubernetesの各レイヤーについて
1-1. Kubernetesとは何か
1-2. コンテナ技術とDocker
1-3. Kubernetesの登場
1-4. Kubernetesの構成
1-5. Kubernetesのオートスケーリング機能について
2-1. Dynatraceを用いたKubernetesの性能管理
2-2. DynatraceでのKubernetesの稼働分析
2-2-1. Cluster単位の分析
2-2-2. Namespace単位の分析
2-2-3. Workload単位の分析
2-2-4. Node単位の分析
2-2-5. Pod単位の分析
2-2-6. Container単位の分析
3-1. Cluster単位の検知
3-2. Namespace単位の検知
3-3. Node単位の検知
3-4. Workload単位の検知
4. まとめ
――――――――――――――――――――――――
本記事では、Kubernetesをご存知ではない方や、Kubernetesの導入を検討されている方に向けて、Kubernetesの基礎を紹介いたします。
下記にて、コンテナ技術の普及に至った背景から、Kubernetesを構成するレイヤーの説明、オートスケーリングによるリソースの自動調整機能を紹介します。
1.Kubernetesとは、Kubernetesの各レイヤーについて
近年、IT運用の現場でKubernetesに対する注目が高まっています。
このオープンソースのコンテナオーケストレーションツール(Container Orchestration Tool)の採用や検討は、スタートアップから大企業に至るまでの幅広い組織で見られ、その柔軟性とスケーラビリティにより、クラウドネイティブなアプローチがビジネスの新しい形として広まりつつあります。
本記事では、KubernetesがIT運用の現場で急速に普及している背景および、主にその性能管理について焦点を当て、Dynatraceがどのようにアプローチできるかをご紹介します。
なお、Kubernetesは常に改善と機能強化を続けており、この記事の内容は執筆時点で確認できた機能や制限でのものとなっております。
あらかじめご了承ください。
1-1. Kubernetesとは何か
Kubernetes(k8s)とは、コンテナ(Container)を効率的に管理するためのオーケストレーションツールです。
Googleによって開発された技術を基にしており、コンテナの自動配置、スケーリング、運用を可能にします。
クラウドに依存しないプラットフォームであり、任意の環境(クラウド、オンプレミス)での運用が可能です。
1-2. コンテナ技術とDocker
Kubernetesが登場する背景として、コンテナ技術の普及がありました。
コンテナ技術自体はKubernetesが登場するよりも前から存在していました。
VMwareなどでは仮想マシンは各々が完全なゲストOSを含むため、より多くのリソースが必要となりますが、コンテナではOSのカーネルを他のコンテナと共有するため、アプリケーションとそのランタイムのみが起動します。
そのため、非常に軽量であるという利点があります。
この仕組みにより、仮想マシンよりもリソース利用効率が高く、短い起動時間を実現しています。
|
利点 |
仮想マシン(VMware) |
コンテナ技術 |
|
効率性 |
各VMには独立したOSが必要で、 リソース消費が大きい |
OSのカーネルを共有し、 リソースを効率的に利用 |
|
起動時間 |
起動には数分かかることが多い |
数秒以内に起動 |
|
スケーラビリティ |
リソース消費が大きいため、 限られた数のVMしか実行できない |
軽量で、同じハードウェア上で より多くのインスタンスを実行可能 |
|
ポータビリティ |
環境間での移行がより複雑 |
アプリケーションと その依存関係をパッケージ化し、 異なる環境間で容易に移行可能 |
|
独立性と隔離 |
ハードウェアレベルでの隔離を提供するが、 オーバーヘッドが大きい |
プロセスレベルでの隔離を提供、 一つのコンテナの問題が他に波及しない |
|
デプロイメント速度と容易さ |
デプロイメントには、 より多くのステップと時間が必要 |
定義された環境を迅速にデプロイ可能、 オーケストレーションツールにより管理が容易 |
|
開発と運用の俊敏性 |
開発と運用のプロセスがより隔離されがち |
DevOpsとの連携が容易、 CI/CDパイプラインへの統合がスムーズ |
図1:仮想化とコンテナの比較表

【図2】仮想化とコンテナの比較構成図
しかし、現代のコンテナ技術が広く使われるようになったのは、Dockerの登場以降です。
コンテナ技術は仮想マシンと比較して性能面での優位性はありましたが、設定の手間がかかるなどの使いにくさやセキュリティ面などの懸念がありました。
2013年に公開されたDockerは、これらの問題を大きく改善し、コンテナの作成、配布、実行を簡単にするツールとして急速に普及しました。
Dockerによって、コンテナ技術は開発者にとってアクセスしやすくなり、それまでの仮想マシンに基づくアプローチに代わる選択肢として注目されるようになりました。
しかし、コンテナ化されたアプリケーションの管理、特に大規模な環境やマイクロサービスアーキテクチャにおける管理は依然として課題でした。
1-3. Kubernetesの登場
Kubernetesは2014年にGoogleによってオープンソース化された、コンテナのオーケストレーションツールです。
コンテナ化されたアプリケーションの運用が大規模になるにつれて増える管理の手間の問題を、デプロイメント、スケーリング、管理を自動化することにより解決しました。
例えば、アプリケーションの負荷に基づいて、リソース※1の割り当てを自動的にスケールアップまたはスケールダウンすることが可能です。
Kubernetesの登場により、仮想マシンではなくコンテナ単位で業務システムを使うことが一般的になりました。
急速に普及しつつあるKubernetesですが、性能管理はどのように行えば良いでしょうか?
オートスケーリングによってリソースが自動的に調整されるとしても、依然、リソース管理や障害発生時の原因分析など、運用上の課題は存在します。
本記事では、弊社で取り扱うツールを用いて、どのようなデータが取得できるのか、また、取得したデータがどのように活用できるのかを、紹介していきます。
(※1)リソースについて、本記事ではCPUおよびメモリを対象に取り扱います。
1-4. Kubernetesの構成
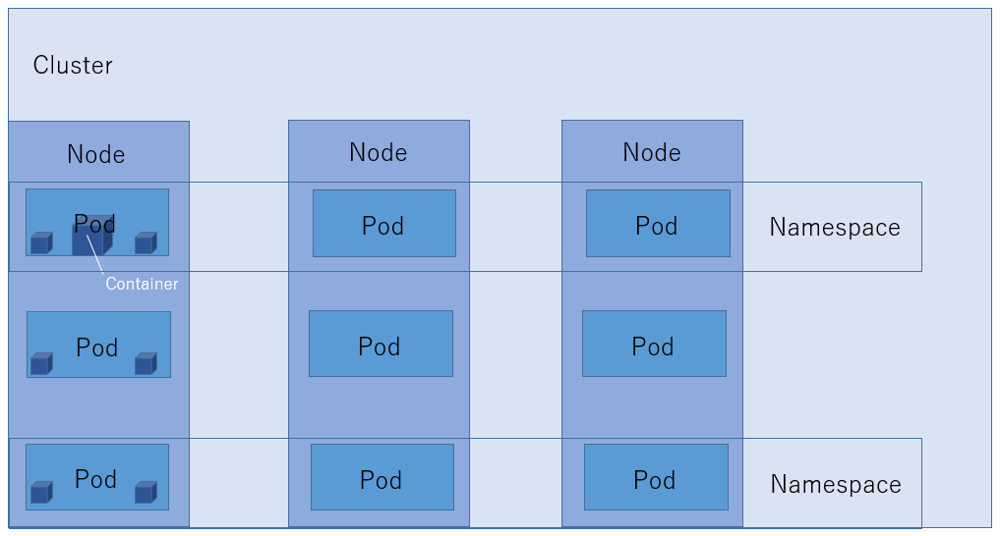
【図3】Kubernetesの簡易的な構成図
続いて、Kubernetesの基本的な構成について、レイヤーごとに役割を紹介します。
・Pod(アプリケーション実行最小単位)
「Pod」は、Kubernetesが制御する最小単位です。Podとは、「群れ」を意味します。
Podは、一つ以上のContainerを含むことができ、これらは同じネットワーク空間とストレージを共有します。
Container自体はアプリケーションの実行環境を提供しますが、Kubernetesが管理するのはそのContainerを包含するPodです。
KubernetesはContainerを直接管理するのではなく、Podという単位を通じてContainer群を効率的に管理します。
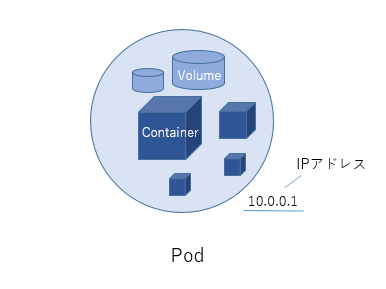
【図4】Podの構成図
・Node(マシン)
複数のPodは、「Node」単位でまとめられています。
Kubernetes Clusterとして連携する、実際の物理マシン、または、仮想マシンのことです。
Nodeには、Kubernetes全体の司令塔となる「Master Node」と、実際にPodを動作させるための「Worker Node」があります。
実行中のアプリケーションのContainer化されたインスタンスを、「Workload」と呼びます。
「Master Node」からAPIによってトリガーされ、「Worker Node」上でWorkloadが実行されます。
Kubernetesのオートスケーリング機能では、リソース需要に応じてNodeの数を自動的に増減させることも可能です。
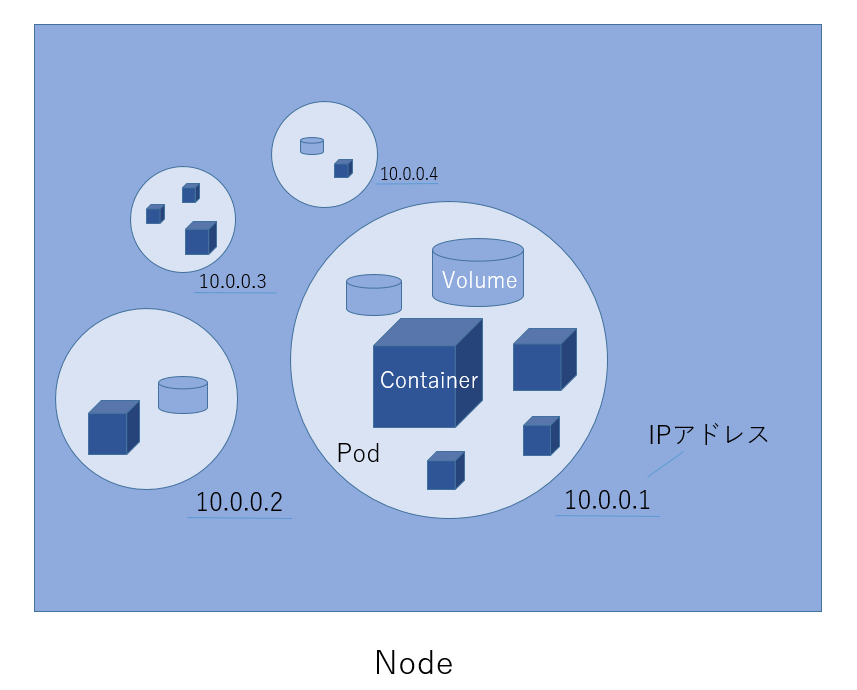
【図5】Nodeの構成図
・Cluster(Nodeマシン群)
Kubernetesの最上位階層にあるのが「Cluster」です。
Clusterとはまとまりを意味します。
Master Nodeから、各Nodeに対し、デプロイや削除といった指示を出します。
複数のContainerに対して、ネットワークやストレージなどの連携管理を実現し、Containerがダウンしたり、アプリケーションに高負荷がかかった場合もスムーズな運用ができる仕組みとなっています。
Kubernetesのオートスケーリング機能はKubernetesの持つ重要な機能の一つです。
ここでは、どのようにしてリソースの需要に応じて1-5. Kubernetesのオートスケーリング機能について、自動的にスケールアップやスケールダウンを行うのか、オートスケーリングのメカニズムについて簡単に解説します。
・リソースのオートスケーリング機能
- 1. Horizontal Pod Autoscaler (HPA/水平スケーリング)
アプリケーションの負荷に基づいて、Podの数を自動的にスケールアップ(増加)またはスケールダウン(減少)します。
例えば、CPU使用率やメモリ使用量があらかじめ設定した閾値を超えた場合に、自動的にPodの数を増やして負荷を分散させることができます。
- 2. Vertical Pod Autoscaler (VPA/垂直スケーリング)
Podに割り当てるリソース(CPUやメモリ)を自動的に調整します。
VPAは、Podのリソース使用状況を監視し、最適なリソース割り当て量を自動的に適用します。
- 3. Cluster Autoscaler
Workloadの変化に基づいて、Cluster内のNodeの数を自動的に調整します。
リソース需要が高まると、新しいNodeを追加しWorkloadが使えるリソースを増やします。
リソース需要が減ると、不要になったNodeを削除します。
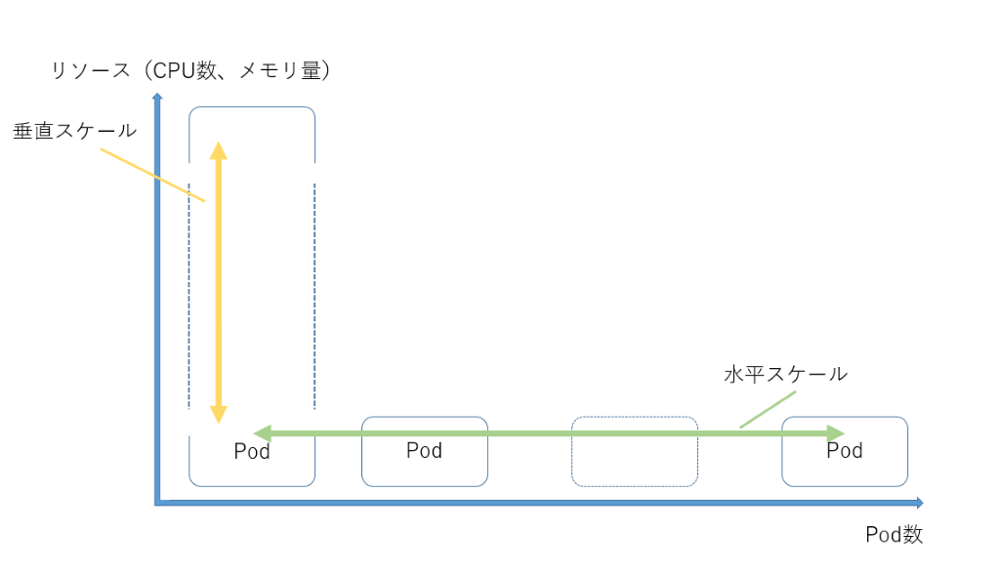
【図6】オートスケーリング機能のイメージ図(HPAとVPA)
<Horizontal Pod AutoscalingとCluster Autoscalingを同時に設定した場合の挙動>
Horizontal Pod Autoscaler(HPA/水平スケーリング)とCluster Autoscalerを同時に設定した場合、負荷が高くなった際に最初に反応してリソースを増やすのは通常、HPAです。理由としては、HPAとCluster Autoscalerが作動するレイヤーに違いがあります。
・HPAの作動
HPAはアプリケーションレイヤーで作動し、Podのメトリクス(例えばCPU使用率やメモリ使用量)を監視します。
負荷が増加し、設定された閾値を超えると、HPAは追加のPodをデプロイして負荷に対応しようとします。
これは比較的迅速に行われ、アプリケーションのスケールアップニーズに直接対応します。
・Cluster Autoscalerの作動
Cluster AutoscalerはClusterレイヤーで作動し、全体のリソース使用状況を監視します。
HPAによって追加のPodが必要とされるものの、既存のNodeに十分なリソースがない場合(全てのNodeでリソースが不足している、またはPodを配置するための適切な容量がない場合)、Cluster Autoscalerが作動します。
Cluster Autoscaler※2は新しいNodeをClusterに追加してリソース容量を増やし、新しく必要とされるPodが配置できるようにします。
(※2)Cluster Autoscaler機能は、クラウドネイティブな環境で多く使われます。オンプレミス環境などでも使用できますが、ネットワークの制約やリソースの物理的な限界などにより、動的なリソースの追加が難しいといった要素があります。
上記のように、Pod、Node単位でのオートスケーリング機能によりリソース需要に対する柔軟なスケーリングは可能となりましたが、割り当てられるリソースが無限にあるわけではありません。
オンプレミスではClusterを構成するNode全体が持つCPU、メモリが限界になる可能性があり、クラウド環境ではコストの限界(仮想マシン追加するたびに使用料金が増えるため)があります。
次回の記事から、Dynatraceを用いて、Kubernetesを対象としたパフォーマンス分析やアラート機能を紹介します。
以上

執筆者
R.Y.
営業技術本部 技術サービス統括部 技術サービス1部
また、お客様環境にて性能問題が発生した際には、製品のアウトプットを利用し、問題解決に向けた調査/提案業務を実施
■経歴
2021年 入社
2022年 東京でのお客さまサポートを担当
主にシステムリソース情報からの性能管理サポート、APM製品を利用したユーザー体感レスポンスやアプリケーション視点での性能管理サポートに従事。現在に至る。
-

#21 Webサイトにアクセスして画面表示されるまで
2024.06.21
ブラウザで画面をクリックして画面が表示されるまでの動作についての解説と、Dynatrace RUMを利用した端末サイドの分析例を紹介します。
-

#20 Dynatraceを用いたKubernetes分析(3/3)
2024.05.14
IT運用の現場では、インフラ構成の選択肢としてKubernetes環境が一般的となりつつあります。今回は「Dynatraceを用いたKubernetes分析」を主軸に、3本の記事構成でご紹介します。 3本目は、アラート機能に焦点を当てて、各種設定やIT運用にどのように役立てられるのかを説明します。
-

#19 Dynatraceを用いたKubernetes分析(2/3)
2024.05.14
IT運用の現場では、インフラ構成の選択肢としてKubernetes環境が一般的となりつつあります。今回は、「Dynatraceを用いたKubernetes分析」を主軸に、3本の記事構成でご紹介します。 2本目は、パフォーマンス分析の観点から、Dynatraceの各画面や手法を紹介します。