

近年の監視課題とObservability
従来の監視手法は、ログやシステムリソースの異常を閾値設定とアラートによって検知し、検知情報から問題や影響を調査する流れだったのでしょうか。
今までのオンプレミスやモノリシックなアーキテクチャであったシステムでは従来の監視手法でも十分にパフォーマンスを監視できていたかと思いますが、近年はシステムのクラウド化が進み、システムの構成が複雑になっています。
それによって従来のリソースやログ監視のみの監視手法だけでは、どこでどんな障害が、何が原因で起こっているか、が分かりにくいという課題が新たに生まれています。
このような課題を解決するために、「Observability(可観測性)」という考え方が重要視されています。
Observabilityとは、システム全体の状態をいつでも把握する仕組み、指標のことをいいます。
Observabilityで重要なのは、
・ログやリソースだけでなく、レスポンス状況やユーザーの業務量といった全ての情報をリアルタイムで把握する
・収集したデータからシステム状況を分析し、ユーザーに対するサービスの提供を維持する
という観点で監視を行うことです。
従来の監視手法にObservabilityの考え方を加えることで、サービス異常を即時に把握し、従来の監視手法では検知することが難しい障害にも迅速に対応することができます。
ダッシュボードを監視に活用する
Observabilityを実現するためには、あらゆるデータを可視化することが重要です。
データを可視化する方法の一つとしてダッシュボードがあります。
ダッシュボードとは様々なデータを一纏めにし、表やグラフにして表示できる機能です。
多くの監視製品にはダッシュボード機能が存在するため、 監視を改善する際に導入しやすい方法になるかと思います。
ダッシュボードを利用すると、システムが今どのような状況なのか、問題が発生しているのか、などを数値やグラフで一目で確認することができます。
監視業務に携わる中で、「問題が発生した際にどこから何を確認すれば良いのか分からない」といった問題に直面することも少なくないかと思います。
そのようなときにダッシュボードを用意しておき、
『何か問題が発生したとき、システム状態を確認したいときにはまずはダッシュボードを確認する』
という運用にすることで、システムの状態を誰でも確認する事が可能となり、問題に対して即時に対応できる環境を作ることができます。
下記ではDynatraceのダッシュボードを例として、ダッシュボードを起点としObservabilityの考え方を取り入れた監視・障害分析手法をご紹介いたします。
ダッシュボードを起点とした監視・障害分析手法
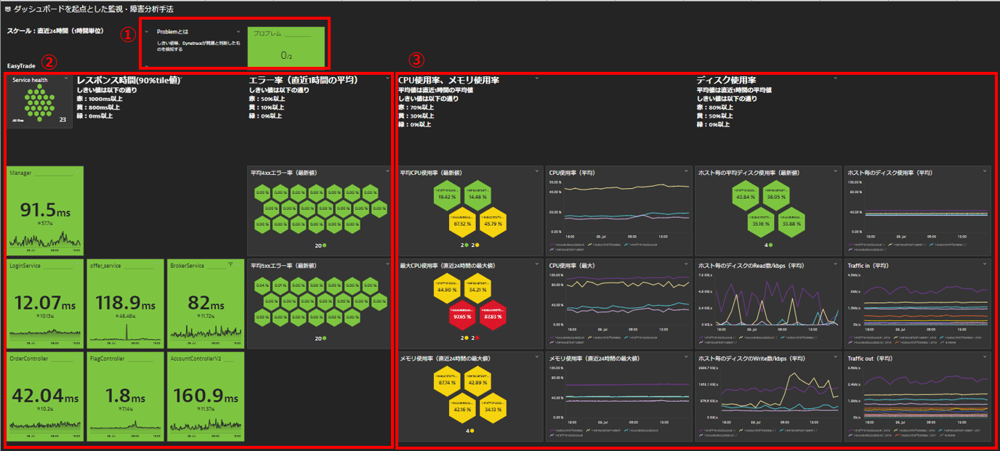
図1 ダッシュボード全体図
今回は「EasyTrade」というシステムを監視するために用意したダッシュボードを例として説明していきます。
このダッシュボードは大きく3つの要素で構成されており、図の①~③へ順番に確認していくイメージとなります。
①対象システムから情報が取得できているか、異常は起きていないか
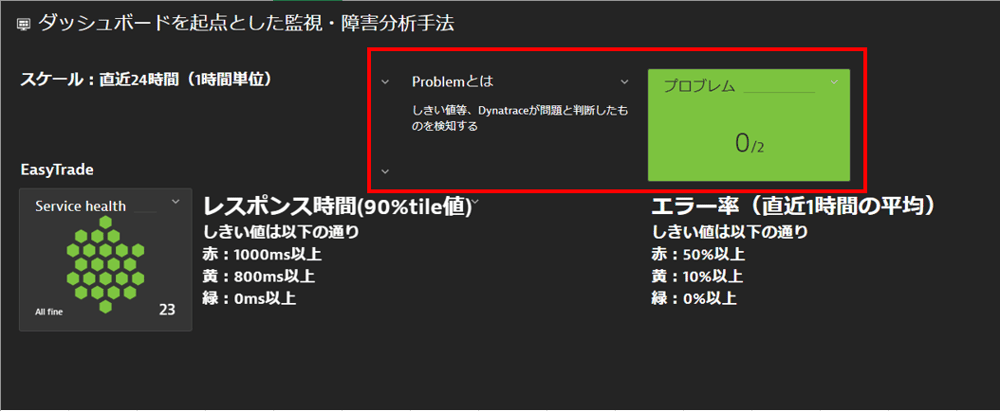
図2 Problem拡大図
まずはじめに、監視状況に異常が見られないかを常に把握しておくことが重要です。
リアルタイムににデータを取得・監視し、対象システムに異常が起きていないかを常に監視できる状態にします。
Dynatraceは何らかの問題が発生して対象システムから情報が取得できなくなったり、レスポンスの遅延などといった異常を検知すると
Problemとして発報します。
ダッシュボード上にProblemが確認できるよう表示することで、運用担当者はダッシュボードを見ればリアルタイムの監視状況を確認することができます。
Problemが発生している場合、以下のような問題が考えられます。
・監視対象サーバー側の問題
・ネットワーク側の問題
・監視ツール側の問題
どの問題が原因であるか、Problemの内容を確認しながら切り分けを行っていきます。
②サービスに影響していないか
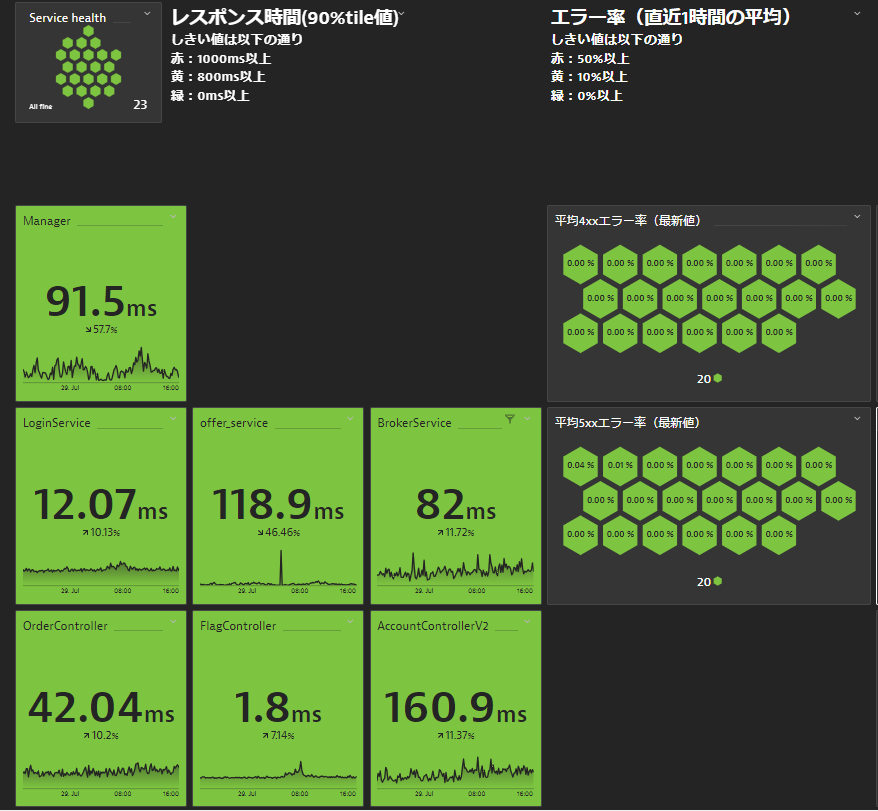
図3 レスポンス時間・エラー率拡大図
Problemが発生していたり、ユーザーから「処理に時間がかかる」などのクレームがあった場合は、サービスに影響しているかどうかを確認します。
冒頭でご説明した通り、Observabilityで重要なのはサービスの提供を維持することです。
サービスの劣化が確認できた場合、サービスの提供は維持できていないため早急に復旧する必要があります。
サービスの劣化を確認する項目として、図3には各サービスのレスポンス時間とエラー率を表示しています。
関連サービスを並列に並べたり、システムの処理順に配置することで、システム構成に詳しくなくても視覚的にシステムの状況を把握することができます。
レスポンス時間の値は90%tile値を設定しています。
90%tile値とは、指定した時間枠のなかで取得したデータ数を100個とした場合、最小値から数え90番目に位置する値を指します。
90%tile値で評価したときの値がしきい値以下であれば、 全体に対して90%のトランザクションはしきい値以下でサービスを提供できており、 適切なレスポンスの範囲でサービスを提供できていると言えます。
エラー率はそれぞれ4xxエラー、5xxエラーが指定した時間枠のなかで平均して何%発生していたかを表示しています。
エラーがどのサービスで増えているのか、クライアント側でエラーが発生しているのか、サーバ側でエラーが発生しているのか、をサービス毎に切り分けることができます。
このように各サービスのレスポンス時間とエラー率をダッシュボード上に表示することで、レスポンス遅延やエラー率の上昇が確認できたサービスを特定することが容易になり、障害対応の時間短縮になります。
また、エラーの影響範囲を確認することができるため、インシデントを管理する上で重要な優先順位の定義も分かりやすくなります。
例:サービスの影響が大きければ"重要度大"、サービスの影響がでていなければ"重要度低"といった形で、優先順位を付けることが可能
です。
③サーバーリソースに変化はないか
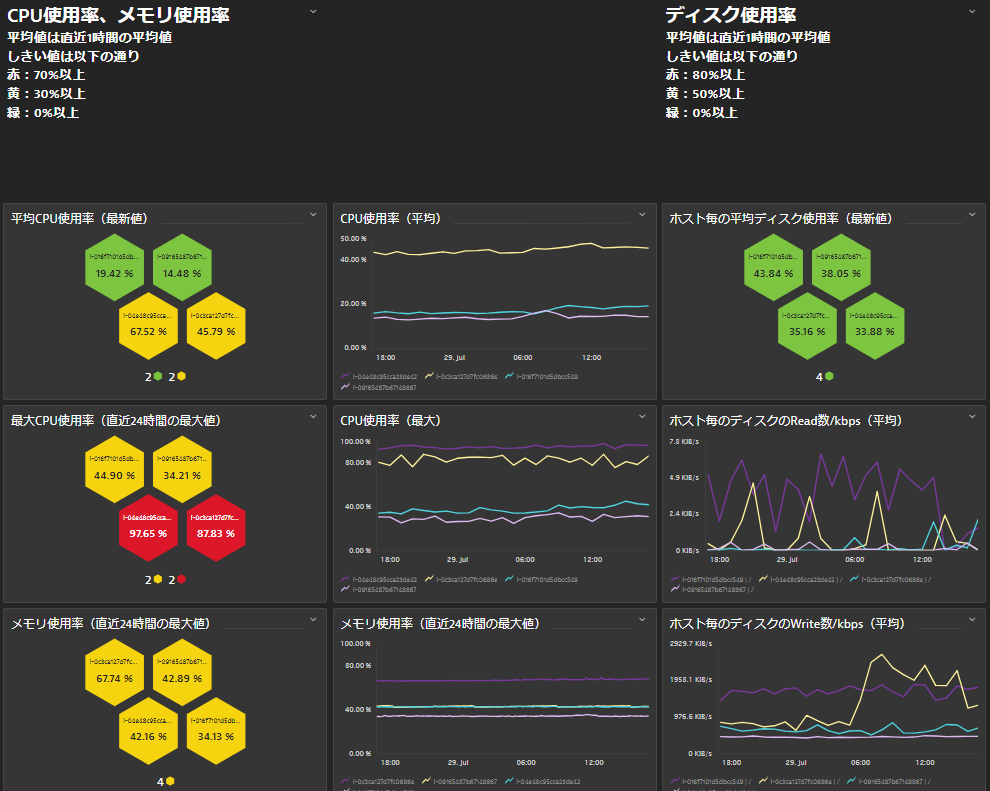
図4 リソースデータの拡大図
次に確認する観点として、各サーバーのリソース状況を確認できるようにダッシュボードに表示します。
図4では、CPU使用率やメモリ使用率、ディスク使用率といった項目をサーバー毎に表示しています。
これによりサービス劣化がサーバーのリソースによるものなのか、それとも別の要因なのかを切り分けすることができます。
まずはCPU使用率を見て、CPUの負荷が高くなっていないかを確認します。
負荷状況を確認するときにはしきい値の設定が重要です。
何%を正常とするか基準値を設定しダッシュボード上にも表示しておくことで、どんな人が見ても同じ判断ができます。
他のサーバーリソースも同様にダッシュボードに表示することで、従来のモニタリングである閾値設定やアラートベースで検知していた障害についても即時に異常を検知し、分析を行うことができます。
そして、②で確認したサービスの状況とあわせて、発生した障害がサービスに対してどの程度影響を与えるかを確認する事ができます。
まとめ
今回は、近年の監視の考え方であるObservabilityを実現する、ダッシュボードを起点とした監視・分析手法についてご紹介いたしました。
「ダッシュボードにどのような情報を表示すれば良いか分からない」という課題を持っていらっしゃる方も少なくないかと思います。
基本的な考え方はどんなダッシュボードでも大きくは変わらないかと思います。
本記事がダッシュボードの運用方法や監視分析の参考になれば幸いです。

執筆者
A.K.
営業技術本部 カスタマーサクセス統括部 カスタマーサクセス部
お客様担当SEとして、製品の構築から活用方法までの一連のサポートを担当
また、お客様環境にて性能問題が発生した際には、製品のアウトプットを利用し、問題解決に向けた調査/提案業務を実施
経歴
2023年入社
2023年4月~ 東日本でのお客さまサポートを担当
主にシステムリソース情報からの性能管理サポート、APM製品を利用したユーザー体感レスポンスやアプリケーション視点での性能管理サポートに従事。現在に至る。
-

#27 DynatraceによるIIS処理遅延の原因分析
2025.07.16
本記事ではIISのセッション管理の仕様が原因となり、深刻なレスポンス遅延が発生した事例をご紹介します。IISのアーキテクチャ、Dynatraceを活用した分析方法をご確認いただけます。
-

#25 Dynatrace Workflowsの検討事例紹介その2
2024.12.12
Dynatrace Workflowsは、Dynatraceで取得した情報をもとにタスクを自動化する機能です。本記事でWorkflowsの検討事例をご紹介することで、皆様のWorkflows利用の後押しとなればと思っています。2本目の記事では、具体的な検討事例をさらにもう2点、ご紹介いたします。
-

#24 Dynatrace Workflowsの検討事例紹介その1
2024.12.12
Dynatrace Workflowsは、Dynatraceで取得した情報をもとにタスクを自動化する機能です。本記事でWorkflowsの検討事例をご紹介することで、皆様のWorkflows利用の後押しとなればと思っています。1本目の記事では、Workflowsの概要と具体的な検討事例2つをご紹介いたします。