

SQL Server搭載サーバーのCPU負荷上昇について、オープンシステム向け性能管理ソフトウェア ES/1 NEO CSシリーズを活用した分析事例をご紹介します。
SQL ServerのCPU負荷調査に至った経緯
-
ES/1 NEO CSシリーズをご利用いただいているお客様から、将来のボトルネック分析のご依頼をいただきました。長期データを確認したところ、DBサーバーの業務時間帯の最大CPU使用率が漸増傾向にあり、DBサーバーのCPU使用率がボトルネック箇所となる可能性があることをご報告させていただきました。(図1)。
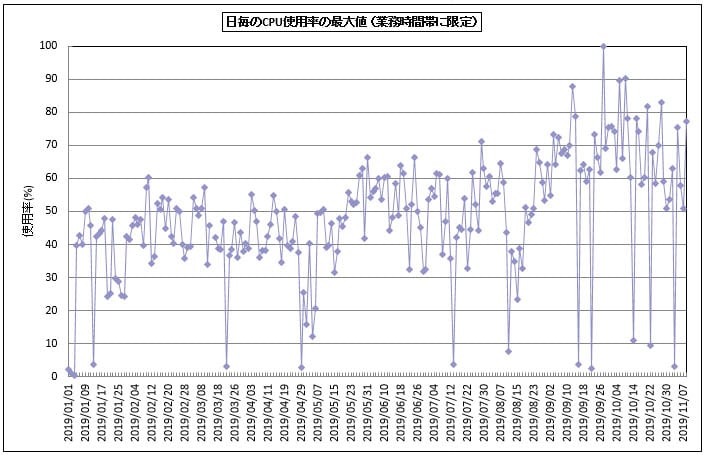
図1 日毎のCPU使用率の最大値(業務時間帯に限定
CPU使用率と相関のある指標:SQL Serverのページルックアップ回数
パフォーマンス指標悪化の原因分析の際、弊社でよく使用するのが相関分析です。複数の項目から、対象の指標と同じ動きをしている項目を見つけるために、相関係数を算出する手法です。相関係数は、Excelの標準関数「CORREL」でも算出できます。弊社では、相関係数0.7以上のものを「関連あり」としています。
結果として、DBサーバーのCPU使用率とSQL Serverのページルックアップ回数の相関係数が最も高いことがわかりました。SQL Serverのページルックアップ回数とは、SQL Serverのデータ参照回数を示します。時系列で見ると、確かにCPU使用率とページルックアップ回数の増加のタイミングが同時期となっていました(図2)。特に5月と8月に増加が顕著となっています。
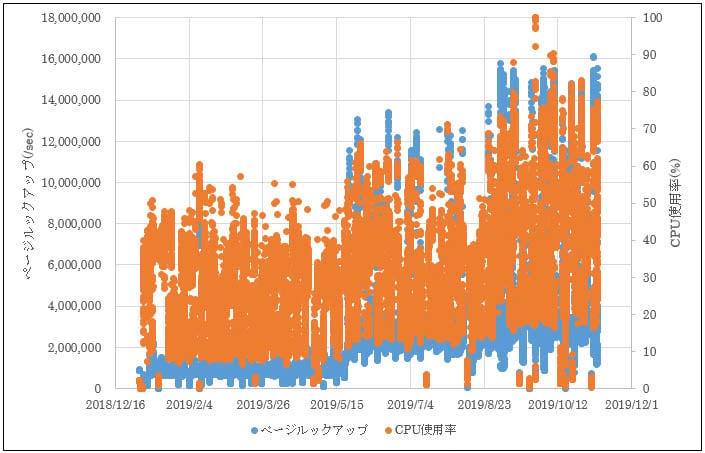
図2 時系列でみるSQL Serverのページルックアップ回数とCPU使用率の推移
SQL Serverのページルックアップ回数増加の原因
-
次に確認したのは、SQL Serverのページルックアップ回数の内訳です。Windowsのパフォーマンスカウンタでは、表1のような内訳を確認することができます。
表1 Windowsのパフォーマンスカウンタで確認できるSQL Serverページルックアップ回数の内訳
| 項目名 | 意味 |
|---|---|
| SQL Server Access Methods Probe Scans/sec | ユニークとなるインデックスを使用したスキャンの回数。例えば、where句で「=」が使われるSQLが該当する。 |
| SQL Server Access Methods Range Scans/sec | インデックス範囲を探索するスキャンの回数。例えばwhere句で「>」「<」が使われるSQLが該当する。 |
| SQL Server Access Methods Full Scans/sec | 全件検索の回数。 |
ページルックアップ回数の内訳をグラフ化したところ、5月にRangeScanが増え、8月にProbeScanが増えていることがわかりました(図3)。RangeScan、ProbeScanともにインデックスを使用したデータ参照となります。
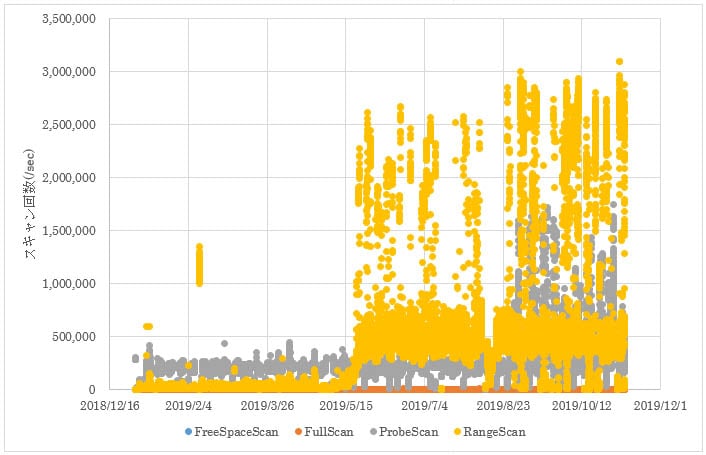
図3 SQL Serverのページルックアップ回数の内訳
さらに、RangeScan、ProbeScanの増加に応じて、ページ分割回数が増加していました(図4)。
ページ分割とは、データページに新たなデータがINSERTされる際、十分な空き領域がないために、データページを分割する処理となります。このとき、データページやインデックスページが分断され、I/O処理の連続性が失われることとなります。これを「インデックスの断片化」と呼びます。
「インデックスの断片化」が発生している場合、インデックスやデータの読み込み回数が増え、CPU使用率も高くなりやすい状況となります。これが、DBサーバーのCPU負荷の原因となっている可能性があることをご報告させていただきました。
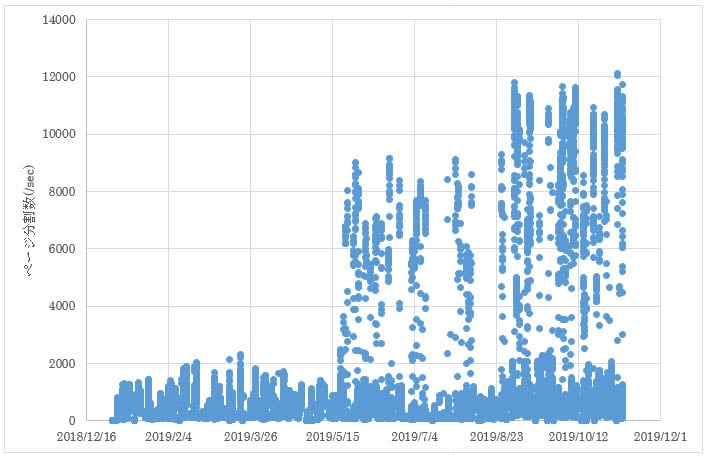
図4 SQL Serverのページ分割回数
SQL Server運用のベストプラクティス
-
インデックス断片化への対処のため、該当のお客様や他社様にインデックス断片化の取り組みについてお聞きしました。その内容を下記に掲載させていただきます。
-
1. インデックス断片化状況の確認
パフォーマンスカウンタの値では、テーブル毎のページ分割数やインデックス断片化率を確認することができません。該当のお客様では、テーブルごとの断片化率の情報をSQL Serverのシステム動的管理ビューのひとつ「sys.dm_db_index_physical_stats」から30分に1回取得する仕組みを構築されていました。 -
2. インデックス再構築の頻度
あるお客様では定期的にインデックスの断片化率を計測され、断片化率が10%を超えたらインデックス再構築を実施する、という運用を実施されていました。他にも、下記のようなテーブルは定期的なインデックス再構築が必要なテーブルと考えられます。 -
<インデックス再構築の検討が必要なテーブル>
・スキャン密度が低い(Average Page Densityが80%以下)
・フラグメンテーションが大きい(Logical Scan Fragmentationが40%以上)
・ページ数が大きい
・アプリケーション使用頻度が高い -
3. インデックス再構築の方法
SQL Serverでは、インデックス再構築のため、2つのコマンドが用意されています(表2) -
【表2 SQL Serverのインデックス再構築のためのコマンド】
| 目名 | 意味 |
|---|---|
| ALTER INDEX REORGANIZE | デフラグに相当する。オンライン実行可能。オンライントランザクションへの影響も軽微。 |
| ALTER INDEX REBUILD WITH (ONLINE = ON) | インデックス再構築に相当する。オンライン実行も可能だが、トランザクションログ、Tempdbを多く利用するため、注意が必要。 |
4. ページ分割の抑制
FILL FACTOR 値により、あらかじめデータページの空き領域を確保しておき、突発的なINSERTによるページ分割を抑制できます。 例えばFILL FACTOR値を80 に指定すると、各ページの 20% が空き領域として確保されます。該当のお客様では、テーブルの特性を踏まえて、70〜100の間で設定しているそうです。
後日談1: インデックス再構築後も断片化率が解消しないテーブルについて
インデックスの再構築を実施し、CPU負荷が安定してきた一方で、急激なページ分割増加とそれに伴うCPU負荷の高騰が発生するタイミングがあると教えていただきました。特に、当日登録分のみを格納しているテーブルがあり、夜間にインデックスを再構築しても翌日には大量のデータがINSERTされ、断片化率が99%となってしまうそうです。
更新頻度の高いテーブルはインデックスを作成しないことも全体効率を上げる対応策となる可能性がありそうです。Microsoft社のページにもそのような注意書きが見られました。
https://docs.microsoft.com/ja-jp/sql/relational-databases/sql-server-index-design-guide?view=sql-server-ver15
後日談2: URLごとのDB時間の管理
インデックスの断片化の他にも、該当のお客様では、毎月の機能拡張や業務内容の変化により、突発的にDB負荷が増加するという課題がありました。その対処として、URLごとのDB時間の管理を行うようになったと教えていただきました。URLごとのDB時間を把握しておくことで、DB負荷高騰の前に対処することが狙いとなります。
APMツール「AppMon」では、ビジネストランザクションというデータ集計機能を使用することで、URL毎のAPI別内訳から、JDBC時間を集計できます(図5)。
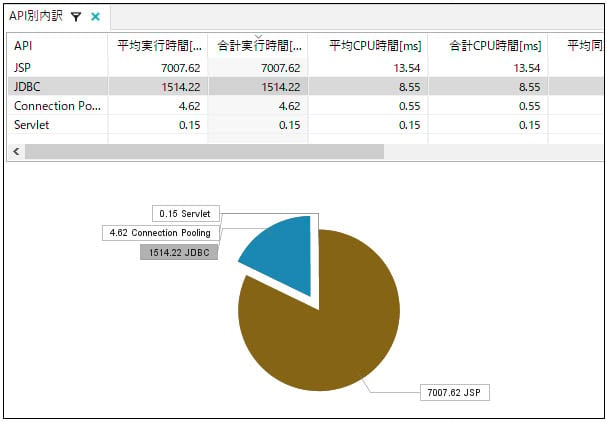
図5 AppMonのURL毎のAPI別内訳
また、AppMonの後継製品である「Dynatrace」では、デフォルト設定のままURL毎のDB時間を集計しています。確認方法としては、ナビゲーションメニューの「Diagnostic tools」から「Multidimensional analysis」を開きます。「Multidimensional analysis」は、Dynatraceで取得したトランザクションデータを様々な集計単位で集計できます。本機能を利用することで、URL毎のDB時間(Time spent in database calls)を確認できます(図6)。
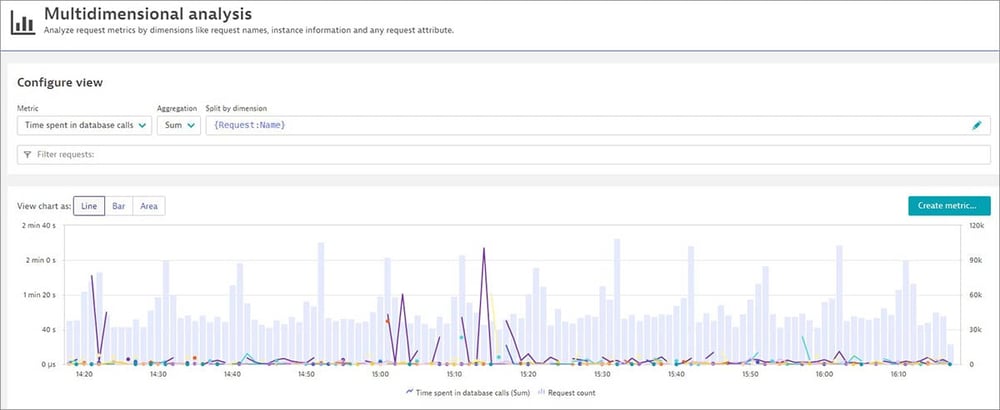
図6 DynatraceのMultidimensional analysisでURL毎のDB時間を抽出
4.まとめ
「インデックスの断片化」は長期運用により発生する問題であり、気付きにくい事象のひとつとなります。しかし、放置してしまうと、SQL Serverのデータ参照回数の増加や、CPU使用率の増加を引き起こし、将来のトラブルの原因となる恐れがあります。ご自身の管理されているデータベースで、インデックスの断片化の対処を実施していない場合には、一度見直してみることをお勧めいたします。

執筆者
N.T.
営業技術本部 技術サービス統括部 技術サービス1部
お客様担当SEとして、製品の構築から活用方法までの一連のサポートを担当
また、お客様環境にて性能問題が発生した際には、製品のアウトプットを利用し、問題解決に向けた調査/提案業務を実施
■経歴
2013年 入社
2014年 品質管理部隊へ配属、10月からお客さまサポート部隊へ異動
主にシステムリソース情報からの性能管理サポートに従事し、近年は、上記に加えAPM製品を利用したユーザー体感レスポンスやアプリケーション視点での性能管理サポートにも従事。現在に至る


