

「データドリブン」「DX」、企業の新たな取り組みとその課題
ITとビジネスを紐づけた分析を実現するためのシステム運用
昨今、「データドリブン(Data Driven)」や「デジタルトランスフォーメーション(DX)」、「AIOps」という言葉を耳にする機会が増え、従来のシステムのパフォーマンス管理だけでなく、ITとビジネスを紐づけた分析を実施しようと、各企業でもこれらの言葉を意識した取り組みが実施されています。
弊社がDynatraceをご提案する中でもこれらの言葉を耳にする機会が多く、Dynatrace社主催のグローバルAPMカンファレンス『Perform 2020』*1 でも取り上げられておりました。
しかしながら、実際に取り組もうとプロジェクトを立ち上げ進めてみたものの、準備に時間を費やしてしまったり、集めたデータを分析してみたものの、次へのアクションとして何をすべきか判断に迷うケースも多いとお聞きします。
そうした際に、パフォーマンス管理ソフトウエア Dynatraceをご利用いただくことで、自動で全てのプラットフォームのデータを収集、可視化、さらには搭載された独自AIエンジンで問題の検知を行い、みなさまのシステム運用のお悩みを解消することが可能です。
本記事では、このDynatraceの独自AIエンジンの秘密を共有し、AIOps実現のためにノイズを大幅に削減し、根本原因の特定を改善する方法について記載いたします。
Dynatraceはデータドリブンの実現を容易にする
Performでは、Dynatraceを利用することでのデータドリブンへのアプローチとして以下のことが挙げられていました。
- すべてのデータを測定
- 正確なデータの提供
- すべてのレベルのユーザーをサポートする事前設定のデータセットとツールの提供
- 部門間の境界を越えてデータと洞察を活用
- データドリブン型文化に執拗に取り組む

写真1:Dynatraceでのデータドリブンへのアプローチ
従来のツールでは、アプリケーションごとにモジュールが異なり、導入方法も複雑でした。しかし、Dynatraceは、共通のモジュールを使用することで簡単に導入することができ、AWSやAzure、VMware環境といった基盤から、サーバー内部の詳細な処理時間、ユーザー視点でのアプリケーションデータなど、システム全体を包括したデータを取得することができます。
また、全てのレイヤーのデータを可視化、および独自AIエンジンが全ての階層を掛け合わせた分析を行い、その結果をひとつのWeb画面でご確認いただけます。
この取得したデータに対し、独自AIエンジンが問題と検知した場合、ProblemsとしてDynatraceの画面への表示や、メールやお客様が普段の運用で使用されている他ツールへ連携し、通知を行います。
Dynatraceをご利用いただくことで、データの蓄積からデータの分析、および問題発生時の原因分析、さらにはその気づきまで、通常かかる多くの時間を削減することが可能になります。
Dynatraceが提供する独自AIエンジン「Davis」
さて、本記事のタイトルを見て「Davisって何?」と思われた方も多いでしょう。
Davis(デイビス)とはDynatraceが提供する独自AIエンジンにつけられた名称です。
Perform会場では、多く目にした「Others guess. Davis knows.」という言葉の通り、人による推測を超える問題解決を提供する、Dynatrace社の独自技術の象徴であるDavisについても多く取り上げられておりました。

写真2:Dynatrace社が提供する独自AIエンジンDavis
Davisの特徴として、Dynatrace社は、
-
システムの課題を自動的に解決するための正確な答えの提供
-
ユーザーが気づく前にパフォーマンスの最適化と自己修復を可能にする
ことを挙げていました。
Davisは数十億の依存関係を早期に処理し、ノイズを排除した問題発生時の根本原因を正確に特定します。
ノイズを排除した検知、「スケールの呪い」からの脱却
先ほど、Davisはノイズを排除した問題発生時の根本原因を正確に特定すると述べました。
システムを管理する上で、しきい値での管理は欠かせないものです。例えば1つの監視項目で週に1度アラートが検知されるとしましょう。ホストが4台の環境では、週に4度のアラートが検知されます。
しかし、大規模環境になればなるほど、監視する項目が増えれば増えるほど、検知されるアラート数は増加し、分析や原因特定に多くの時間を費やすことになります。
監視項目が4つになり、ホストが10台あればその数は40回です。もっと監視項目や台数が増えるとどうでしょう。Dynatrace社は固定のしきい値管理において、規模と監視項目が増えれば増えるほど検知する数が増えることを「スケールの呪い」と講演しておりました。
この「スケールの呪い」から脱却するために、Davisでは固定のしきい値ではなく、動的なベースラインを作成し、そのベースラインから逸脱したものを検知するしくみが搭載されております。
また、メトリックごとの検知だけでなく複数の項目を掛け合わせ、ユーザー体感レスポンスの低下など、ユーザーに影響があったものを1つのProblemとしてまとめて検知および自動で原因分析を行います。
その原因分析の中にはその事象に関連するメトリックの値がまとめて表示されるため、担当者は複数の項目を個々に調査する必要がなく、いち早くユーザー体感に影響があった問題のみの確認および分析が可能です。
つまり、全てのプラットフォームに対応していることで、メトリックに依存せず、インフラストラクチャからビジネスに直結するユーザー体感の影響についての確率的予測を行い、迅速な意思決定とITリソースにより最適化を可能にします。
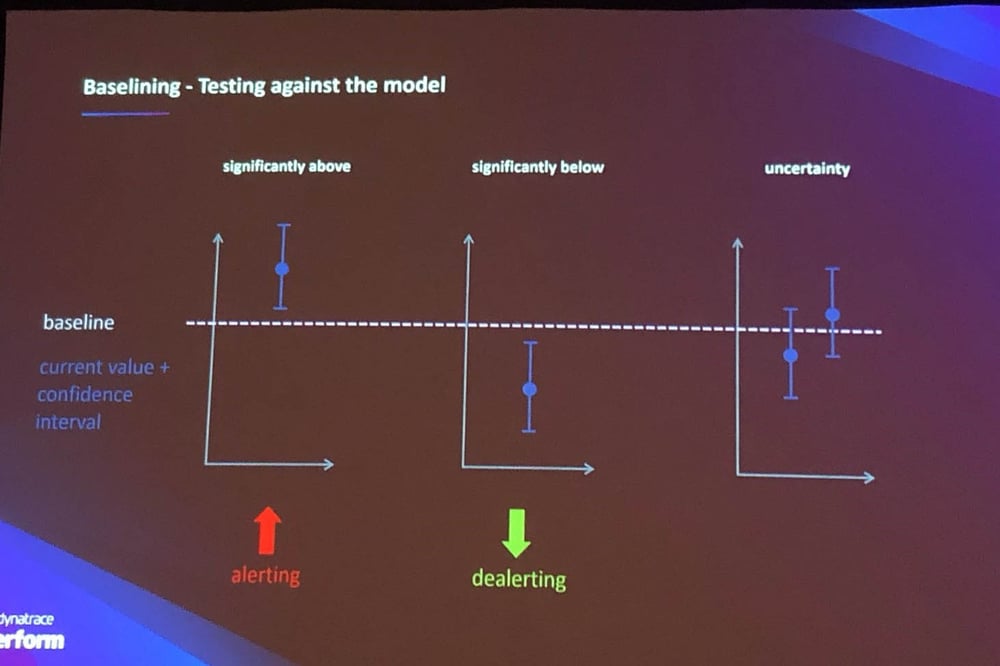
写真3:ベースラインに対するテスト
まとめ
従来のシステムのパフォーマンス管理だけでなく、ITとビジネスを紐づけた取り組みを実現するためには、全てのレイヤーのデータを取得し、ユーザーのパフォーマンスに影響する問題について素早く分析、対処することが求められます。
しかしながら、全てのレイヤーのデータを別々のツールで収集し、それを掛け合わせた分析を人手で行うことには多くの時間を要します。また、固有のしきい値では大規模になればなるほどノイズも多く、ひとつひとつの問題の分析に取り組んでいくことは困難です。
Dynatraceを導入することで、1つのツールで全てのレイヤーをカバーし、そのデータを掛け合わせ、異常値を省いた分析をDavisが自動で行います。原因特定まで自動で実施することで、改善策の検討や新しいリリースへの時間を割くことができ、利用ユーザーの満足度向上などの、ITとビジネスを紐づけた取り組み実施への手助けを行います。
*1 Perform 2020:Dynatrace社主催のグローバルAPMカンファレンス(米国/欧州/アジアで開催)

執筆者
K.N.
営業技術本部 技術サービス統括部 技術サービス1部
お客様担当SEとして、製品の構築から活用方法までの一連のサポートを担当
また、お客様環境にて性能問題が発生した際には、製品のアウトプットを利用し、問題解決に向けた調査/提案業務を実施
■経歴
2014年 入社
2015年~ 2018年2月まで西日本でのお客さまサポートを担当
2018年~ 東日本のお客さまサポート部隊へ異動
主にシステムリソース情報からの性能管理サポートに従事し、近年は、上記に加えAPM製品を利用したユーザー体感レスポンスやアプリケーション視点での性能管理サポートにも従事。現在に至る
-

#25 Dynatrace Workflowsの検討事例紹介その2
2024.12.12
Dynatrace Workflowsは、Dynatraceで取得した情報をもとにタスクを自動化する機能です。本記事でWorkflowsの検討事例をご紹介することで、皆様のWorkflows利用の後押しとなればと思っています。2本目の記事では、具体的な検討事例をさらにもう2点、ご紹介いたします。
-

#24 Dynatrace Workflowsの検討事例紹介その1
2024.12.12
Dynatrace Workflowsは、Dynatraceで取得した情報をもとにタスクを自動化する機能です。本記事でWorkflowsの検討事例をご紹介することで、皆様のWorkflows利用の後押しとなればと思っています。1本目の記事では、Workflowsの概要と具体的な検討事例2つをご紹介いたします。
-

#22 ダッシュボードを起点とした監視・障害分析手法
2024.08.27
Dynatraceのダッシュボードを例として、ダッシュボードを起点としたObservabilityな監視・障害分析手法をご紹介いたします。